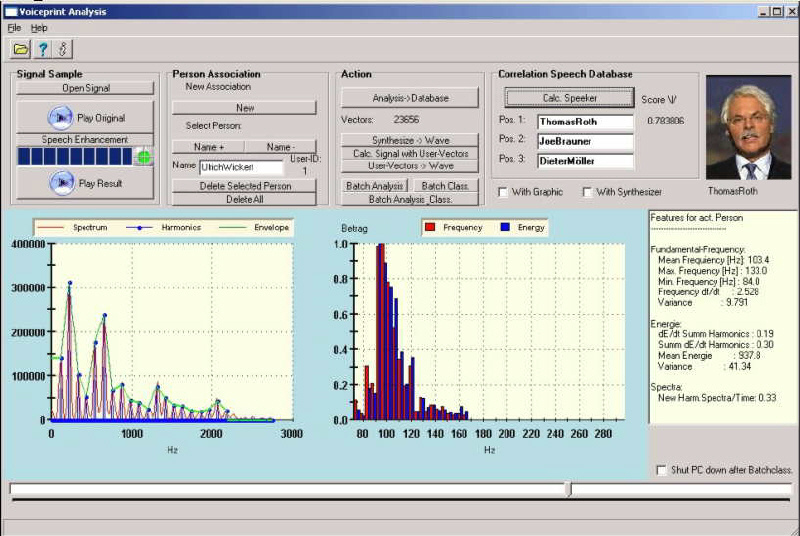
Voice Print Analysis - Sprechererkennung
Die Personenidentifizierung anhand der Stimme als weiteres biometrisches Merkmal gewinnt aufgrund des weltweit gestiegenen Sicherheitsbedürfnisses zunehmend an Bedeutung. Attraktiv ist ferner der relativ geringe apparative Aufwand, wobei gleichzeitig Aspekte verfügbarer Rechenleistung für anspruchsvolle Softwarelösungen mehr und mehr in den Hintergrund treten.
Die Literatur bietet bereits heute zahlreiche Ansätze zur Lösung dieser Aufgabe, wobei jedoch in allen bekannten Fällen die menschliche Leistungsfähigkeit zur Personenidentifikation anhand der Stimme noch unerreicht ist. IND beteiligt sich an diesem Evolutionsprozess mit einer eigenen Lösung, die auf Basis eines neuen Spracherzeugungsmodells das Signal adaptiv akkurat analysiert, dabei Laute wie
- Vocale
- Nasale
- Frikative und
- Plosiv - Laute
von einander trennt, Merkmale extrahiert und für eine Datenbankkorrelation aufbereitet.
Außerdem besitzt das Verfahren adaptive Störunterdrückungstechniken, die einen Betrieb auch in gestörten Umgebungen erlauben.
Beispiel: Steuerung der Voice-Print-Engine
Adaptive Störungsunterdrückung, Speech-Enhancement
Egal, ob die IND-Sprechererkennung zur
- Sprecheridentifizierung, hierbei liegt keine Kenntnis über den tatsächlichen Sprecher vor
- Sprecherverifizierung, es existiert eine Annahme des tatsächlichen Sprechers, wobei eine Verfifizierung durch Datenbankvergleich erfolgt
eingesetzt wird: Eine Störungsunterdrückung mit Speech-Enhancement steigert die Erkennungsqualität bzw. ermöglicht erst eine akkurate Arbeitsweise. Die folgende Darstellung zeigt ein Messergebnis der Wahrscheinlichkeit korrekter Sprecherverifikation vs. Störungspegel.

Die rote Kurve (Off) zeigt die mit ansteigendem Rauschpegel absinkende Verifikationswahrscheinlichkeit ohne Speech-Enhancement, während die grüne Kurve (On) die Wahrscheinlichkeit korrekter Verifikation bei permanent zugeschalteter Störreduktion darstellt. Man erkennt, dass ein nicht oder wenig gestörtes Signal durch jegliche Art der Bearbeitung an Qualität einbüssen muss, während andererseits ein stark gestörtes Signal ohne Speech-Enhancement kaum zu verifizieren ist. Aus diesem Grund besitzt die Software eine Automatik, welche je nach Signalqualität die Störreduktion zuschaltet. Auf diese Weise gelangt man zur blau gestrichelten Kurve (Auto), welche in jeder Signalsituation das Optimum des Verifikiationsgrades darstellt.
Weiter: Software